Datalog is a declarative logic programming language that's normally used in deductive databases. A deductive database works by using known facts and a set of rules to determine (deduce) new facts. This is useful for a couple of reasons the main one being that you are able to express relationships that are really cumbersome (or downright impossible) in relational databases.
Datalog Syntax & Semantics
Being a declarative language the syntax itself is very simple. The short version is that statements are divided into adding facts, adding rules and querying the database (which is when the deduction is done). One other action that can be performed is retraction which removes a fact from the database although it is less common in practice. There is no single canonical implementation for Datalog so syntax varies to some degree.
parent(mary, jane).
parent(bob, john).
ancestor(X, Y) :- parent(X, Y).
ancestor(X, Y) :- parent(X, Z), ancestor(Z, Y).
parent(A, B)?
parent(bob, john)~
- The first 2 statements above add 2 new facts to the database i.e
maryis the parent ofjaneandbobis the parent ofjohn1. - The next 2 statements are a rule describing how to tell if one person is another's ancestor, specifying that they are an ancestor if they are someone's parent or a parent of that person's ancestor.
- The next rule is a query which has two variables
AandB, anytime there is a variable2 in a query the Datalog engine tries to find an assignment to that variable that is either a known fact or a derivable fact. Soparent(A, B)?finds all the parent-child pairs in the database. - The last statement is a retraction and just removes the corresponding fact from the database.
This is roughly all you need to know to understand the rest of this article. I have glossed over a lot of details so give the [appendix][appendix] a look if you want to know more.
pyDatalog
The WikiPedia page for Datalog lists a number of implementations and for the Python programming language, the one listed is pyDatalog. It implements the core Datalog functionality as well as some extensions that make it useful in a wider range of problems. The Datalog syntax is embedded in Python so the previous statements become:
+ parent("mary", "jane")
+ parent("bob", "john")
ancestor(X, Y) <= parent(X, Y)
ancestor(X, Y) <= parent(X, Z) & ancestor(Z, Y)
parent(A, B)
- parent("bob", "john")
The exact way to use the library is described in the documentation with
some additional information shown in code inside the examples directory
of the pyDatalog repository.
Using Datalog as a Knowledge Base
The deductive capabilities of a Datalog system make it a good candidate
for a knowledge base because on top of being able to store things you
know, you can store how to find out things you don't. For my particular
case I decided to store package information from pacman the Arch Linux
package manager. Querying pacman for a package's information you get the
following output:
Name : clang
Version : 9.0.1-1
Description : C language family frontend for LLVM
Architecture : x86_64
URL : https://clang.llvm.org/
Licenses : custom:Apache 2.0 with LLVM Exception
Groups : None
Provides : clang-analyzer=9.0.1 clang-tools-extra=9.0.1
Depends On : llvm-libs gcc compiler-rt
Optional Deps : openmp: OpenMP support in clang with -fopenmp
python: for scan-view and git-clang-format [installed]
llvm: referenced by some clang headers [installed]
Required By : opencl-mesa
Optional For : None
Conflicts With : clang-analyzer clang-tools-extra
Replaces : clang-analyzer clang-tools-extra
Installed Size : 98.28 MiB
Packager : Evangelos Foutras <evangelos@foutrelis.com>
Build Date : Mon 30 Dec 2019 01:58:04 EAT
Install Date : Thu 02 Jan 2020 21:06:06 EAT
Install Reason : Explicitly installed
Install Script : No
Validated By : Signature
As you can see there is a bunch of useful information. Finding the
information associated with a single package is easy enough but
plain text was long ago proven to be a poor database. A relational
database could work but fields like Depends On and Required By
necessitate multiple tables for the sake of normalization which
already makes things annoying.
Here's where Datalog comes in, each item a package Depends On
can be stored as a single fact and be accessed just as easily. Practically
though there are a few hoops to jump through before getting to the
Datalog bit the first being extracting the package information. At first
I was simply parsing the output of pacman -Qi <pkgname> like what is
above but it's not really machine friendly. Luckily there's another tool
expac which provides printf like functionality with package
information. The extraction function ends up becoming rather simple:
def get_package_info(pkgname):
info = {}
expac_fmt = ["%n", "%L", "%S", "%E", "%o", "%N"]
prog = ["expac", "-Q", "\\n".join(expac_fmt), pkgname]
keep = (
"Name",
"Licenses",
"Provides",
"Depends On",
"Optional Deps",
"Required By",
)
with subprocess.Popen(prog, stdout=subprocess.PIPE, text=True) as proc:
for i, line in enumerate(proc.stdout):
if i == 0: # Name field
info[keep[i]] = line.rstrip()
elif line == "\n": # This field is empty
info[keep[i]] = []
else:
info[keep[i]] = re.split(r"\s{2,}", line.rstrip())
return info
Once the information about a package is collected into a dictionary, the next step is putting it in a Datalog database.
@pyDatalog.program()
def _():
for pkg in all_packages(): # list of all installed packages
pkg_info = get_package_info(pkg)
name = pkg_info.pop("Name")
+is_pkg(name)
for i in pkg_info.pop("Licenses"):
+has_license(name, i)
for i in pkg_info.pop("Depends On"):
+depends_on(name, i)
for i in pkg_info.pop("Required By"):
+required_by(name, i)
for i in pkg_info.pop("Provides"):
+provides(name, i)
for i in pkg_info.pop("Optional Deps"):
+odepends(name, i)
optional_for(X, Y) <= odepends(Y, X)
diff_license(X, Y, A, B) <= depends_on(X, Y) & has_license(X, A)\
& has_license(Y, B) & (A != B)
diffs = diff_license(A, B, C, D).data
create_correlation_plot(diffs)
There's a couple of things worth mentioning about the above snippet.
Firstly, you normally have to first declare the identifiers you will use
in your pyDatalog statements with a line like pyDatalog.create_terms(...)
but the pyDatalog.program() decorator allows you to skip this step. It
runs the function it decorates making sure to call create_terms on any
unbound identifiers in the body. You have to be really careful with this
as you can end up with some subtle bugs in the form of unintentionally
creating terms you don't need. The decorator also functions like a main
function for you program.
You can probably guess what most of the function body does from our
discussion so far. is_pkg acts as a way to register the packages we
have and allows you to easily check if a certain package's information is
present. The subsequent set of for loops add some facts like the names of
a package's dependencies. Using our clang package as an example, that
means that a fact like depends_on("clang", "llvm-libs") is added.
After the facts is our first rule optional_for(X, Y) which adds a rule
that enables you to find the set of packages that is optional for some
particular package. As you can see this information is already in the
database albeit in a different form as the odepends (Optional Deps)
fact. With Datalog we can see that it is easy to add rules that align the
data more closely to our mental model.
The second rule is a lot more interesting. diff_license(X, Y, A, B)
taken piecewise consists of:
depends_on(X, Y)finds a packageXthat depends on packageYhas_license(X, A)finds the licenseAfor packageXhas_license(Y, B)finds the licenseBfor packageY(A != B)ensures that licenseAandBare not the same
With this rule added, a query diff_license(A, B, C, D) finds all
the packages where its license and that of a dependency differs. For
example one of the values returned would be ('clang', 'gcc', 'custom:Apache 2.0 with LLVM Exception', 'GPL'). Pretty cool! The equivalent SQL
is not nearly as simple probably requiring at least a JOIN.
Visualizing the Relationship
A bunch of (package, package, license, licence) tuples are good to have
but what we really want to know is how likely a package with a given
license has a dependency with some other particular license. More
concretely, how likely is it that a GPL licensed package has a MIT
licensed dependency. I'll skip the code and go straight to the result this
time3.
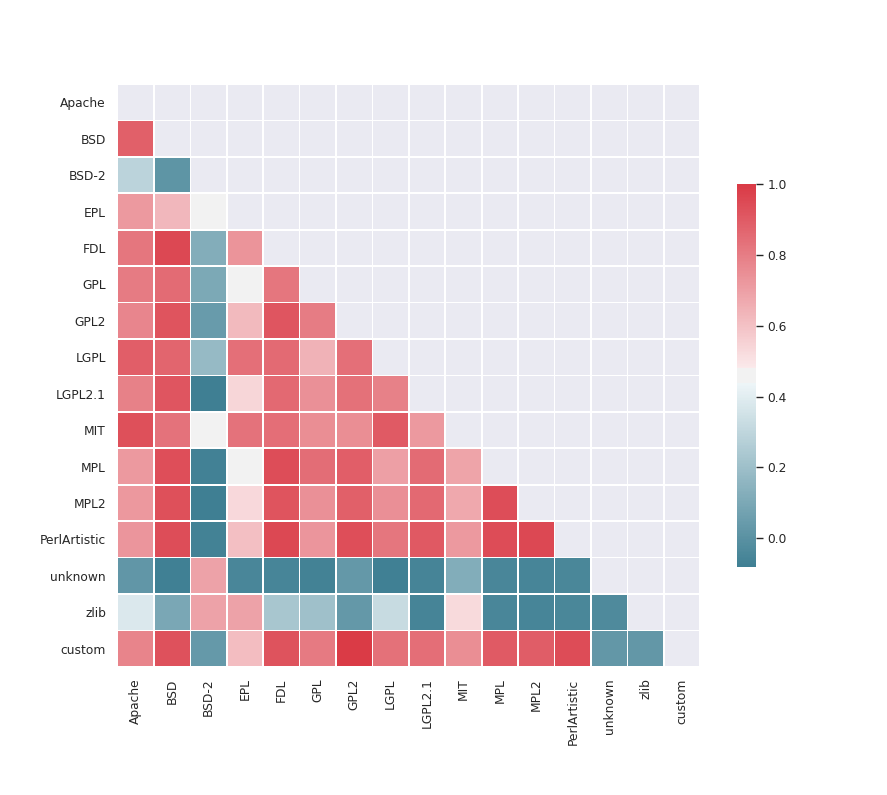
There's a lot more you can do with this sort of Datalog backed package database that I'm in the process of working out. I promise to update this article with any other interesting results I obtain.
Appendix
- The Racket Datalog implementation comes with a simple tutorial
- The Lua Datalog implementation is also decent.
- This article gives a nice introduction to deductive databases.
- A detailed source of information on Datalog can be found in this (old) paper.
- Datafun offers a functional version of Datalog.
- The book Foundations of Databases contains a chapter about Datalog.
- The full code can be found here
Uppercase letters represent variables which you are trying to find the value of. Lowercased identifiers occurring inside brackets represent literal values similar to symbols in Scheme.
↩A variable does not need to be unique across statements and represent totally different things depending on where they occur.
↩The visualization code can be seen in the full code listing
↩